동적 SQL의 축복과 저주
동적 SQL의 축복과 저주
원문: SQL Server MVP Erland Sommarskog의 SQLText
번역: quest, ASP MVP(microsoft.public.kr.asp.qna)
Microsoft SQL Server에 대한 여러 뉴스그룹에서 왜 다음 쿼리가 불가능한 지를 문의하는 사람들을 종종 보게 된다.
SELECT * FROM @tablename
SELECT @colname FROM tbl
SELECT * FROM tbl WHERE x IN (@list)
많은 경우에 간략한 예와 함께 "동적 SQL을 사용하세요"라는 답변이 달리곤 하지만, 답변하는 사람들조차 동적 SQL문의 사용시에 주의해야할 사항에 대한 언급을 잊는 경우가 많다.
이 기사에서는 MS SQL Server의 저장프로시저에서 동적 SQL의 사용에 대해 살펴보고, 조심스럽게 다루어야할 여러 강력한 특징들에 대해 얘기하고자 한다. 그런 특징들에 대해 설명하기 전에, 우선 왜 저장프로시저를 사용해야 하는 지에 대해 논의할 것이다. 그 다음에 저장프로시저를 사용함으로써 얻는 장점과 동적 SQL 효과 간에 충돌에 대해 얘기해 볼 것이다. SQL Injection이라고 알려진 일반적인 보안문제에 대해 언급하고, 몇가지 좋은 코딩 습관에 대해 알아보고자 한다. 마지막으로, 동적 SQL이 좋은 해결책으로 활용되는 경우와 그렇지 못한 경우에 대해 살펴볼 것이며, 후자의 경우에는 대신 사용 가능한 방법을 제안하고자 한다.
왜 저장프로시저를 사용하는가?
동적 SQL이 실제로 무엇인가를 살펴보기 전에, 왜 저장프로시저를 사용해야 하는지를 먼저 알아볼 필요가 있다. 저장프로시저를 사용하지 않고 클라이언트(※역주: 여기서의 클라이언트는 SQL서버에 대한 클라이언트를 의미합니다. 웹프로그램 개발의 경우 웹서버가 여기에 해당하며, 클라이언트 코드는 ASP와 같은 Server Side Script를 의미합니다.) 혹은(COM+와같은) 중간층(middlelayer)에서 직접 SQL문으로 이루어진 명령문을 내보내는 복잡한 응용프로그램을 작성할 수도 있다. 세련되어 보이기 때문에 저장프로시저를 사용하는 것은 아니며, 이에는 분명 장점이 존재한다.
1.권한 체계 (The Permission System)
저장프로시저는 사용자들에게 데이타에 대한 제한적인 접근을 허용케하는 전통적인 수단이다. 쿼리분석기와 같은 도구를 이용할 경우 원하는 어떠한 작업도 수행가능하므로, 사용자들은 SELECT, INSERT, UPDATE 혹은 DELETE 같은 문장을 직접 실행할 수 있는 권한을 가져서는 안된다. 예를들어, 권한을 가진 사용자가 직원 데이타베이스에 접근하게 될 경우, 쉽게 봉급을 인상시킬 수 있다. 저장프로시저를 사용하면, 해당프로시저의 실행은 프로시저 소유자의 권한을 이용하게 되므로, 사용자들은 테이블에 대한 직접적인 권한을 필요로 하지 않게 된다.
요즘은 이 상황에 대해 몇 가지 선택 가능한 사항이 더 존재한다. 사용자 계정에 직접 권한을 부여하기 보다는, 비밀번호가 필요한 고정서버역할(applicationrole)에 접근 권한을 부여할 수 있으며, 그런 비밀번호를 응용프로그램 안에 숨겨둘 수 있다. SQL 서버에서 고정서버 역할은 7.0버전부터 지원 되었으며, COM+와 같은 중간층을 사용하면 사용자가 SQL 서버에 직접 접근할 필요가 없다는 점에서 더 안전하다.
하지만 고정서버 역할이나 COM+ 등을 사용하지 않는다면, SQL 서버보안 측면에서 저장프로시저는 여전히 중요한 의미를 가진다.
2.실행 계획 캐쉬 (Caching Query Plans)
저장프로시저를 사용하는 다른 중요한 이유는 성능을 향상시키기 위해서이다. 저장프로시저가 최초로 실행되면, SQL 서버는 해당프로시저에 대한 실행계획을 생성시키며, 이 실행계획이 캐쉬에 저장된다. 해당 저장프로시저가 재실행 요청을 받으면, SQL 서버는 저장된 실행 계획을 재사용한다. 실행 계획이 만료되거나 혹은 SQL 서버가 새로운 실행 계획을 생성시켜야 할 이유가 생길 때까지 해당 실행 계획은 캐쉬에 유지된다.(이 과정은 프로시저가 실행되는 동안에 일어나는데, 여기에 대한 논의는 이 기사의 범위를 벗어난다.)
SQL 서버는 저장프로시저 외부에서 실행되는 SQL 문장들에 대한 실행 계획도 캐쉬한다. 자동 매개 변수화 과정(auto-parameterization) 또한 수행되어, 만약 다음과 같은 문을 실행시킬 경우,
SELECT*FROMpubs..authorsWHEREstate='CA'
go
SELECT*FROMpubs..authorsWHEREstate='WI'
SQL 서버가 쿼리를 다음과 같이 캐쉬하므로, 2번째 Select문장은 첫 번째 문장의 실행 계획을 재사용한다.
SELECT * FROM pubs .. authors WHERE state=@1
SQL 문장이 좀 더 복잡해질 경우에는, SQL 서버가 자동 매개 변수화에 실패할 수도 있다. 심지어 유사한 쿼리문에서 공백문자(whitespace)의 차이로 인해 SQL 서버가 캐쉬에서 해당 문장을 찾는데 실패하는 경우를 본 적도 있다. 결론은 SQL 서버가 순수 SQL 문장을 캐쉬하는 데에도 좋은 성능을 발휘하지만, 저장프로시저를 사용하는 경우 쿼리 실행 계획의 재사용 확률이 더 높다는 것이다.
작고 짧은 실행시간을 가지며 자주 실행되는 SQL문 혹은 저장 프로시저의 경우에 캐쉬는 더욱 중요한 의미를 가진다. 실행계획을 만드는데 500ms가 소요되면 상당한 과부하가 될 수도 있기 때문이다. 반면에, 20분동안 실행되는 프로시저의 실행계획을 세우는데 3초가 소요되는 것은 대단한 문제가 아니다. 만약, 아직도 SQL 6.5를 사용하고 있다면, 해당 버전의 SQL 서버는 순수한 SQL 문에 대한 캐쉬를 하지 않으며, 저장 프로시저에 대한 실행계획만을 캐쉬에 저장한다는 사실을 알아야 한다.
다면, 결과 집합으로 값을 받는 것에 비해 @key를 출력매개변수로 반환받는 경우의 이점은 엄청나게 커지게 된다.:INSERT tbl (...) VALUES (...)
SET @key = @@identity
5. 업무규칙 모듈화 (Encapsulating Logic)
이것은 보안 혹은 성능향상과 관련된 것은 아니지만, 코드를 모듈화하는 방법의 하나이다. 저장 프로시저를 사용하면, SQL 문을 만들어내기 위해 클라이언트 코드와 씨름할 필요가 없다. 하지만, 이러한 이유때문에 저장 프로시저를 사용해야 한다고 말할 수는 없다. (SQL 코드가 클라이언트측 주요 언어의 문법에 묻혀 버리기는 하겠지만) 여전히 여러 매개변수들로부터 SQL 문을 조합하는 것이 가능하다.
좀 특별한 경우를 예로 들어 보겠다: 만약 쿼리 분석기 외의 다른 응용프로그램이 없다면, 관리자들을 위한 저장 프로시저를 작성하게 된다는 말이며, 이런 경우에는 저장 프로시저가 업무규칙 모듈화를 위한 유일한 수단이 된다.
6. 의존성 파악 (Keeping Track of what Is Used)
수백개의 테이블이 존재하는 복잡한 시스템에서, 간혹 어디에서 어떤 테이블 혹은 칼럼이 참조되었는지 알고 싶을 때가 있다. 이를테면, 만약 칼럼을 변경할 경우에 어떤 일이 일어날지 알고 싶은 경우가 있을 수 있다. 만약 모든 코드가 저장 프로시저에 보관되어 있다면, 참조된 개체를 찾기 위해 저장 프로시저의 코드만 살펴보면 된다. 또는 간단히 변경하고자 하는 칼럼 혹은 테이블을 누락시킨 데이타베이스를 생성시켜 어떤 일이 일어나는지 관찰할 수도 있다. 시스템 테이블 sysdepends와 시스템 저장 프로시저 sp_depends를 이런 목적에 사용할 수도 있지만, sysdepends내에 보관된 정보를 온전히 정확하게 유지시키기는 어렵다.
응용프로그램에서도 순수 SQL 문을 사용가능하도록 허용 한다면, 문제는 더욱 심각해진다. 훨씬 많은 양의 코드를 살펴봐야 하며, status와 같은 일반적인 이름을 가진 칼럼들은 놓치기도 쉽다. 그리고 sysdepends는 완전히 무의미하게 된다.
EXEC()와 sp_executesql
MS SQL 서버에서 동적 SQL을 실행시키는 2가지 방법은 EXEC()와 sp_executesql이다.
EXEC()
EXEC()는 다음 예제와 같이 그 사용법이 아주 간단하다.:
SELECT @table = 'sales' + @year + @month
EXEC('SELECT * FROM ' + @table)
비록 위의 예가 상당히 단순해 보이지만, 여기에는 놓쳐서는 안될 중요한 점이 존재한다. 첫번째 중요한 점은 비록 해당 문장이 저장 프로시저 내에 존재하더라도 현재 사용자의 권한으로 실행된다는 것이다. 두번째로 중요한 것은 EXEC()가 저장 프로시저의 실행을 위한 EXEC와 매우 유사하다는 점이다. 하지만 이 예제에서는 저장 프로시저를 호출하는 대신에, 단일 SQL 문을 일괄실행시켰다. 마치 저장 프로시저를 호출할 때처럼, 해당 일괄실행문은 호출하는 저장 프로시저와는 다른 실행범위(scope)를 가지게 된다. 여기에는 몇가지 중요한 의미가 내포되어 있다.:
- SQL 일괄실행문 안에서는 호출하는 저장 프로시저의 지역변수 혹은 매개변수에 접근할 수 없다.
- USE 문의 사용이 호출하는 저장 프로시저에 영향을 미치지 않는다.
- SQL 일괄실행문에서 생성된 임시 테이블은 일괄실행문이 종료되면 삭제(drop)되기 때문에, 마치 저장프로시저가 종료된 경우와 마찬가지로, 호출하는 저장 프로시저에서 접근할 수 없다. 그러나, 일괄실행문 내부에서는 호출하는 저장 프로시저에서 생성된 테이블에 접근가능하다.
- SQL 일괄실행문 내에서 SET 문장을 사용하면, SET 문장의 영향력은 일괄실행문 내부에서만 유지된다.
- SQL 일괄실행문의 실행계획은 호출하는 저장 프로시저의 실행계획의 일부가 아니다. 해당 쿼리문의 캐쉬여부는 클라이언트 프로그램에서 SQL 문장만을 사용하는 경우와 동일하다.
- SQL 일괄실행문이 (트리거내의 Rollback처럼) 일괄실행을 종료시키는 결과를 낳았을 때는, 동적 SQL의 일괄처리가 종료될 뿐만 아니라, 호출하는 저장 프로시저 (그리고 해당 프로시저를 호출한 다른 저장 프로시저도) 역시 종료된다.
정상적으로 저장 프로시저를 호출할 때와는 달리, EXEC()문에서는 매개변수 혹은 반환값을 사용할 수 없다. @@error 값은 일괄실행문의 마지막 문장의 실행결과에 관계가 있다. 그러므로, EXEC()내부에서 에러가 발생하더라도 뒤따르는 명령문이 성공적으로 수행되었다면, @@error는 0의 값을 가지게 된다.
EXEC()는 SQL 6.0에서 도입되었다.
EXEC(@sql)와 EXEC @sp를 혼돈하지 말아라. 후자는 이름이 @sp인 저장 프로시저를 실행시킨다.
sp_executesql
sp_executesql는 SQL 7에서 도입되었으며, 동적 SQL 문자열 내부로 입력과 출력을 위한 매개변수를 전달할 수 있다는 장점이 있다. 출력 매개변수를 사용하는 간단한 예는 다음과 같다.
(※ 역주 : sysname은 nvarchar(128)과 같은 기능의 시스템 제공 사용자 정의 데이타 형식으로 데이타베이스 개체 이름을 참조할 때 사용됩니다.)
DECLARE @sql nvarchar(4000),
@col sysname,
@min varchar(20)
SELECT @col = N'au_fname'
SELECT @sql = N'SELECT @min = convert(varchar(20), MIN(' + @col + N')) FROM authors'
EXEC sp_executesql @sql, N'@min varchar(20) OUTPUT', @min OUTPUT
SELECT @min
이 장점으로 인해, 동적 SQL 문을 사용할 때 EXEC()에 비하여 sp_executesql을 사용하면 지역변수로 값을 받아내기가 훨씬 쉬워졌다. (EXEC()에서도 INSERT EXEC()를 이용하여 동일한 작업을 수행할 수 있지만, 수월하지는 않다.)
sp_executesql의 첫번째 인자는 SQL 문(Unicode 문자열)으로, SQL 문법상 변수가 허용되는 곳에는 매개변수를 사용할 수 있다. (그러므로, 여전히 칼럼이름 혹은 테이블이름에 변수를 사용할 수는 없다). 매개변수의 데이타 형은 ntext이어야 하므로, nvarchar 형식의 변수를 사용하여야 한다. SQL 문이 상수로 전달되려면, Unicode 형식임을 나타내기 위해 N 접두어를 인용부호 앞에 붙여야 한다. SQL 문에는 @로 시작하는 매개변수가 포함될 수 있는데, 여기에 사용되는 매개변수들은 동적 SQL문의 외부에서 사용된 변수와는 전혀 별개의 변수이다. sp_executesql에서 사용되는 SQL 문에는 다른 곳에서 사용되는 SQL 문과 마찬가지의 문법이 적용되므로 여전히 칼럼명 혹은 테이블명에는 변수를 사용할 수는 없으므로, 동적으로 결정되는 경우에는 조합시킬 문자열 내에 포함시켜야 한다.
sp_executesql의 두번째 인자는 저장 프로시저 선언부와 마찬가지의 문법으로 매개변수 및 기본값이 정의된 매개변수 정의 목록이다. (온라인 도움말에는 매개변수에 대한 설명이 누락되어 있다.) 매개변수 정의 목록 역시 ntext 데이타 형이다. SQL 문장에서 사용된 모든 변수는 매개변수 선언목록에 명시되어야 한다.
sp_executesql의 나머지 인자는 매개변수 선언목록에서 선언된 것들로, 이들은 선언된 순서로 사용되거나 혹은 변수 이름과 같이 사용가능하다.
sp_executesql는 여러가지 이유로 인해 EXEC()보다 선호된다. sp_executesql 를 사용하면, 사용자가 직접 매개변수를 제공할 수 있기 때문에, SQL 서버가 매개변수 자동화를 수행하도록 의존할 필요가 없다는 것도 그 이유중의 하나이다. 그러므로, sp_executesql를 사용하면 캐쉬 사용의 가능성이 더 높아진다. (그래도 여전히 공백 문자의 사용은 주의를 기울여야 한다.) SQL injection 및 좋은 코딩 습관에 대한 얘기를 하면서 sp_executesql의 다른 장점에 대해 다시 언급할 것이다.
EXEC()에 대해 얘기되었던 특징들은 sp_executesql에도 마찬가지로 적용된다.:
- SQL 코드는 고유한 실행범위(scope)를 가지므로, 호출한 저장 프로시저에서 변수에 접근할 수 없다.
- 현재 사용자의 권한이 적용된다.
- USE 문장의 사용이 호출한 저장 프로시저에 영향을 미치지 않는다.
- 호출한 저장 프로시저에서 SQL 일괄실행문에서 생성된 임시 테이블을 사용할 수 없다.
- SQL 일괄실행문내에서 사용된 SET 문장은 일괄실행문 내에서 영향력을 가지지만, 호출한 저장 프로시저에는 영향을 미치지 않는다.
- sp_executesql에 의해 실행된 일괄실행문이 종료되면 호출한 저장 프로시저도 종료된다.
- @@error는 동적 SQL 코드 내부의 최종 실행문의 상태를 반영한다.
온라인 도움말(Books Online)에 의하면, sp_executesql은 성공했을 경우 0, 실패했을 경우 1의 반환값을 가지지만, 최소한 SQL 2000에서 반환값은 @@error의 값과 같다.
sp_executesql에 대한 더욱 자세한 정보는 온라인 도움말을 참조하기 바란다. KB Article 262499은 출력매개변수의 특징에 대해 기술하고 있다.
어느 것을 사용해야 할까? (Which to Use)
동적 SQL을 규칙적으로 사용하는 경우에는, sp_executesql이 최선의 선택이다. sp_executesql의 사용시에는, 실행계획이 재사용될 가능성이 높고, 매개변수를 사용할 수 있기 때문이다. 아직 SQL 6.5를 사용하고 있는 경우를 제외하면, EXEC()를 사용해야 하는 경우는 동적 SQL 문이 nvarchar(4000)의 범위를 넘어서는 경우 뿐이다. 다음과 같이 사용가능하다.
EXEC(@sql1 + @sql2)
T-SQL에서 저장 프로시저를 호출할 때 매개변수로 연산식을 사용할 수 없는 것처럼, sp_executesql를 호출할 때도 하나의 변수만 매개변수로 사용할 수 있다. 만약, 반드시 분리된 쿼리문을 써야 한다면, sp_executesql를 EXEC()내에 포함시켜 사용할 수 있다.:
DECLARE @sql1 nvarchar(4000),
@sql2 nvarchar(4000),
@state char(2)
SELECT @state = 'CA'
SELECT @sql1 = N'SELECT COUNT(*)'
SELECT @sql2 = N'FROM authors WHERE state = @state'
EXEC('EXEC sp_executesql N''' + @sql1 + @sql2 + ''',
N''@state char(2)'',
@state = ''' + @state + '''')
이런 경우에 인용부호(')를 여러번 겹쳐 사용하는 것이 혼란스럽다면 EXEC()만 사용할 수도 있다. (뒷부분에 제시될 사용자 정의함수(UDF; User Defined Function)인 quotestring()을 사용하면 이런 문제점을 해소할 수 있다.)
커서(Cursors)와 동적 SQL
커서는 자주 사용될 뿐만 아니라, 동적 SQL에서의 커서 사용에 대한 질문도 자주 접하게 되므로, 완성도 측면에서 예를 들도록 하겠다. DECLARE CURSOR EXEC()와 같이 사용할 수는 없지만, Declare Cursor문 전체를 동적 SQL에 포함시켜 사용하는 것은 가능하다.:
SELECT @sql = 'DECLARE my_cur CURSOR FOR SELECT col1, col2, col3 FROM ' + @table
EXEC sp_executesql @sql
위 쿼리의 실행에는 로컬 커서(local cursor)를 사용할 수 없다는 것에 주목하라.(로컬 커서는 EXEC(@sql) 문이 종료되는 시점에서 접근불가능하게 되어 버리기 때문이다.) Anthony Faull이 다음 예제에서와 같이 사용할 경우, 로컬 커서를 동적 SQL과 함께 사용할 수 있다고 지적해 주었다.
DECLARE @my_cur CURSOR
EXEC sp_executesql
N'SET @my_cur = CURSOR FOR SELECT name FROM dbo.sysobjects; OPEN @my_cur',
N'@my_cur cursor OUTPUT', @my_cur OUTPUT
FETCH NEXT FROM @my_cur
명명된 커서(Named Cursors)처럼 커서 변수에 접근가능하며, 예제에서 보이는 바와 같이 매개변수로 전달가능하다.
동적 SQL과 저장 프로시저
저장 프로시저를 사용하는 이유와 동적 SQL을 사용할 때 어떤 일이 일어나는지에 대해 살펴보자. 다음과 같은 프로시저를 사용하는 것으로 시작한다.:
CREATE PROCEDURE general_select @tblname nvarchar(127), @key key_type AS -- key_type is char(3)
EXEC('SELECT col1, col2, col3
FROM ' + @tblname + '
WHERE keycol = ''' + @key + '''')
앞으로 살펴 보겠지만, 이것은 전혀 의미없는 프로시저이다. 왜냐하면, 저장프로시저 사용시에 얻을 수 있는 거의 모든 장점을 살리지 못하기 되기 때문이다. 클라이언트 코드에서도 Select 문을 조합해서 SQL 서버에 바로 질의하는 것이 가능하다.
1. 권한 (Permissions)
사용자가 테이블에 직접 접근할 수 있는 권한이 없다면, 동적 SQL을 사용할 수 없다는 것은 너무나도 당연하다. 사용자가 Select 권한을 가지고 있는 환경도 있을 수 있다. 하지만, 권한이 문제되지 않는다는 것을 확신하지 못할 경우에는, 영구 테이블(permanent tables)에 대한 Insert, Update 및 Delete 문을 동적 SQL문에 사용해서는 안된다. 임시테이블을 사용하는 경우에는 아무런 권한 문제가 발생하지 않는다.
사용자들이 데이타베이스에 대한 직접적인 연결을 하지 않고, 고정 서버 역할(application roles)을 활용하거나 COM+와 같은 중간층을 사용하는 경우에는 이 문제에 대해 심각하게 생각할 필요는 없다. 하지만, SQL injection 절에서 여전히 고려해야할 다른 보안 문제에 대해 살펴볼 것이다.
Sysadmin 고정서버역할을 가진 사용자가 사용할 코드를 작성할 경우에는, 당연히 권한문제에 대해 걱정할 필요가 없다.
2. 실행계획 캐쉬 (Caching Query Plans)
살펴본 바와 같이, SQL 서버는 순수 SQL 문과 저장 프로시저 모두에 대해 실행계획을 캐쉬하지만, 저장 프로시저에 대한 실행계획을 재사용할 때 다소 더 정확하다. SQL 6.5 에서는 매실행시마다 재컴파일 되었기 때문에, 동적 SQL이 더 느리다고 확실히 말할수 있었으나, 그 이후 버전에서는 상황이 그렇게 명확하지는 않다.
앞에서 나왔던 general_select 프로시저를 보자. @tblname을 다르게 줄 경우, 실행계획은 캐쉬되고, @tblname에 대한 매개변수 자동화 과정이 일어난다. 이것은 클라이언트 코드에서 SQL 문을 생성시킨 경우에도 마찬가지이다.
이것이 의미하는 바는, 동적 SQL을 현명하게 사용한다면, 성능향상 효과를 얻을 수 있다는 것이다. 예를 들어, 저장 프로시저 내부에 복잡한 쿼리가 있고, 선호되는 실행계획이 실행 당시의 테이블에 있는 데이타에 의존한다고 가정하자. 해당 쿼리를 동적 SQL로 작성하고, SQL 서버가 충분히 똑똑해서 캐쉬된 정보를 전혀 쓰지 않기를 바랄 수 있다 (임시테이블이 사용되었다면, SQL서버가 똑똑하게 처리하지 못할 것이다.). 한편, 그 복잡한 쿼리를 각각의 목적에 맞는 저장 프로시저로 나누어서 같은 결과를 얻을 수도 있겠지만, 모든 로직이 한 군데에 위치한다면 코드는 훨씬 읽기 쉬울 것이다. 위의 내용은 사용자가 동적 SQL을 실행시킬 수 있도록 권한구성이 되어있을 경우를 가정하였다.(?)
3. 네트워크 소통량 최소화 (Minimizing Network Traffic)
앞의 두 절에서 저장프로시저내의 동적 SQL은 클라이언트에서의 평범한 SQL문에 비해 장점이 없다고 하였는데, 네트워크 소통량 문제에 대해서는 그렇지 않다. 저장 프로시저 내에 동적 SQL을 사용하면, 네트워크 비용이 들지 않는다. 예제 프로시져인 general_select의 사용시에는, 이러한 장점이 거의 없으며, 순수 SQL 코드의 크기와 저장 프로시져를 호출하기 위한 실행문의 크기가 거의 비슷하다.
그러나, 복잡한 조건에 따라 6개의 테이블을 조인시키는 복잡한 쿼리를 생각해 보자. 사용자가 필요로 하는 자료의 기간정보에 따라 필요한 테이블은 sales0101이 될 수도, sales0102 가 될 수도 있다. 사실 이런 테이블 디자인은 좋지 못한데, 이에 대해서는 다시 살펴보기로 하고, 아무튼 여러분이 이런 상황에 처해있다고 가정해 보자. 이런 문제를 해결하기 위해 동적 SQL과 저장프로시저내를 활용한다면, 전체 쿼리를 매번 질의하지 않고 기간정보만 매개변수로 전달하면 된다. 만약 쿼리가 시간당 한번 질의된다면, 이득은 무시할만 하겠지만 네트워크 사정이 그렇게 좋지 못한 환경에서 15초마다 한번씩 쿼리를 보내야 한다면 차이점을 느낄 수 있을 것이다.
4. 출력매개변수 사용 (Using Output Parameters)
출력매개변수를 얻을 목적만으로 저장프로시저를 사용하는 경우 동적 SQL의 사용과 별다른 관련성이 없다. 다른 말로, 클라이언트에서 직접 sp_executesql문을 사용할 수 있으므로, 저장 프로시저없이도 출력매개변수의 사용이 가능하다.
5. 업무규칙 모듈화 (Encapsulating Logic)
저장프로시저에 대한 이전 주제에서 다루어진 것들 외에 특별히 더할 내용은 없다. 그럼에도 불구하고 저장 프로시저를 사용하기로 결정한다면 SQL에 관련된 모든 숨겨야할 내용을 저장프로시저내에 포함시킬 수 있다는 점은 지적하고 싶다. 이러한 의미에서 general_select의 예에서 테이블 이름을 매개변수로 직접 전달하는 것은 좋지 못한 생각이다. (sysadmin 고정 서버 역할의 구성원을 위한 응용프로그램의 경우는 예외이다.) 6. 의존성 파악 (Keeping Track of what Is Used)
동적 SQL은 이 목적에 위배된다. 동적 SQL은 sysdepends를 사용하지 않으므로 참조되는 개체파악이 힘들어지며, 데이타베이스 내에 참조되는 개체가 존재하지 않는 경우에도 알아차리기 어렵다. 테이블이름 혹은 칼럼 이름을 매개변수로 사용하지 않을 경우에는, 어떤 테이블이 사용되었는지를 파악하려면 최소한 SQL 코드를 뒤져보는 작업을 해야 할 것이다. 그러므로, 동적 SQL을 사용할 때에는 테이블 이름과 칼럼 이름을 프로시켜 코드에 제한해서 사용하라.
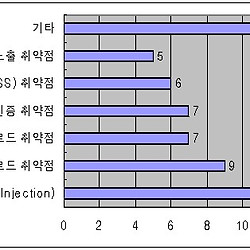
SQL Injection - 심각한 보안 문제
SQL injection 은 공격자로 하여금 개발자가 의도하지 않은 SQL 문을 실행시킬 수 있게 하는 기술이다. 사용자가 입력한 값이 직접 SQL 코드로 전달될 때 (저장 프로시저에서 동적 SQL을 사용하거나 혹은 클라이언트 쪽에서 SQL문을 생성시키거나), SQL injection의 위험이 존재한다. 이 공격방법은 MS SQL 서버뿐만 아니라, 모든 관계형 데이타베이스 관리시스템(RDBMS)에 적용된다.
다음과 같은 저장 프로시저에 대해 생각해 보자.:
CREATE PROCEDURE search_orders @custname varchar(60) = NULL,
@prodname varchar(60) = NULL
AS
DECLARE @sql nvarchar(4000)
SELECT @sql = 'SELECT * FROM orders WHERE 1 = 1 '
IF @custname IS NOT NULL
SELECT @sql = @sql + ' AND custname LIKE ''' + @custname + ''''
IF @prodname IS NOT NULL
SELECT @sql = @sql + ' AND prodname LIKE ''' + @prodname + ''''
EXEC(@sql)
매개변수 @custname와 @prodname 에 대한 입력은 사용자 입력필드로부터 직접 전달되는 값이다. 여기서, 심술궂은 사용자가 @custname에 전달된 입력필드에 다음과 같은 값을 전달한다고 가정해보자. ' DROP TABLE orders --결과로 만들어지는 SQL문은 다음과 같다.: SELECT * FROM orders WHERE 1 = 1 AND custname LIKE '' DROP TABLE orders --'
붉은 색으로 표시된 문장이 보이는가? 이런 공격유형의 성공여부는 상황에 따라 다르다. SQL 서버에 직접 접속한 평범한 사용자가 테이블을 삭제(drop)할 수 있는 권한을 가진다고 보기는 어렵지만, 만약 그 사용자가 웹에서 접속한 사용자이고, 웹서버가 SQL서버에 관리자 권한으로 연결되어 있다면, 해당 공격은 성공하게 될 것이다. 이러한 정밀한 공격에 필요한 권한을 가지고 있지 않더라도, 공격자는 여전히 원하는 명령을 내릴 수 있는 수단을 갖게 된다.
공격자는 먼저 입력필드에 작은 따옴표(')를 넣었을 때 어떤 일이 일어나는지 살펴본다. 만약 문법 오류 (syntax error)가 발생한다면, 공격자는 취약점이 존재한다는 것을 알게 된다. 그런 다음, 공격자는 쿼리를 종료시킬 수 있는 다른 수단을 찾아내고, 결국 자기 자신이 작성한 SQL 명령을 더할 수 있게 된다. 마지막으로 공격자는 SQL 문장의 나머지를 무시하고 문법 오류를 피하기 위하여 주석 문자를 사용한다. 공격자가 세미콜론(;)과 같은 문자를 사용할 수도 있다. SQL 7 이후 버전에서는 세미콜론이 T-SQL 문장을 분리하기 위한 선택사항으로 사용된다. 세미콜론을 사용하여 오류가 발생한다면, 공격자는 general_select에서와 같은 문제점이 존재한다는 것을 알아차리게 된다. 만약 사용자가 입력한 값이 직접 매개변수 @tablename에 전달된다면, 다음과 같은 문장을 전달하는 것도 가능하다:
some_table WHERE keycol = 'ABC' DELETE orders
사용자가 직접 값을 넣을 수 있는 입력필드만 공격에 이용되는 것이 아니라는 것을 기억해야 한다. 저장 프로시저에 직접 전달되는 값이 URL에 포함되어 있다면, 공격자가 이것을 이용할 수도 있다.
이런 공격에는 기술도 필요하겠지만, 운도 많이 작용할 거라고 생각할 수도 있을 것이다. 하지만, 인터넷에는 시간이 널널한 수많은 공격자가 존재한다는 걸 기억해야 한다. SQL injection은 심각한 보안문제이며, 이에 대항하기 위한 방법을 알아야 하다. 이를 위한 2가지 방법이 존재한다.
- 사용자에게 SQL 서버에서 필요한 권한 이상을 부여하지 마라. 응용프로그램이 중간층(middle layer)을 이용하여 SQL 서버에 접속한다면, 테이블에 대한 Select 권한만을 가지는 평범한 사용자 계정으로 접속케 해라. 경험이 적거나, 적당히 얼버무리는 개발자들이 SQL injection이 가능케하는 헛점을 만들 수 있기 때문이다.
- 간단히 적용가능한 코딩 습관이 있는데, 다음 절 "동적 SQL을 위한 코딩 습관"에서 이에 대해 살펴볼 것이다.
SQL injection 문제는 저장 프로시저에 제한된 문제만은 아니라는 것을 강조해야 겠다. 문자열 변수는 종종 제한없이 사용가능하므로, 클라이언트 코드에서 SQL 명령문을 생성시켜 전달할 때 더 큰 취약점이 존재할 수도 있다. 저장 프로시저를 사용하는 경우에도, 호출하기 위해 EXEC문을 텍스트로 전달해야 한다는 것을 기억해야 한다. 여기에 SQL injection 공격이 가능한 취약점이 존재한다.
좋은 코딩 습관과 동적 SQL
동적 SQL을 사용하는 것이 어렵지 않게 보이겠지만, 작성한 코드에 대한 통제를 잃는 경우를 피하기 위한 규칙들이 존재한다. 주의를 기울이지 않는다면, 작성해 놓은 코드가 지저분해지거나 읽기 어렵게 되고, 문제해결을 위한 시도나 유지보수가 어렵게 된다. 무시무시한 프로시져 general_select을 다시 살펴보자.
CREATE PROCEDURE general_select @tblname nvarchar(127),
@key key_type AS -- key_type is char(3)
EXEC('SELECT col1, col2, col3
FROM ' + @tblname + '
WHERE keycol = ''' + @key + '''')
여기서 사용된 중복된 인용부호를 보고 이게 도대체 무슨 뜻이지?라며 자문할 수도 있을 것이다. SQL은 문자열 제한자를 문자열에 포함시키기 위해 해당 리터럴을 겹쳐써야 하는 언어중 하나이다. 따라서, 위의 네개의 작은 따옴표('''')는 하나의 작은 따옴표(')를 표현하기 위한 문자열 리터럴이다. 위에서는 간단한 예를 들었지만, 상황은 더 나빠질 수도 있다.
쉽게 저지르게 되는 다음과 같은 에러가 있다.:
EXEC('SELECT col1, col2, col3
FROM' + @tblname + '
WHERE keycol = ''' + @key + '''')
FROM 다음에 공백이 생략된 것이 보이는가? 해당 프로시저를 컴파일 할때는 에러메시지가 보이지 않지만, 실행시키려로 하면 열 이름 'col1'이(가) 잘못되었습니다., 열 이름 'col2'이(가) 잘못되었습니다., 열 이름 'col3'이(가) 잘못되었습니다., 열 이름 'keycol'이(가) 잘못되었습니다.라는 에러메세지를 접하게 된다. 그러면, 입력된 테이블 이름이 정확하므로 칼럼이름이 잘못된 것으로 오해하게 되어, 혼란이 가중된다. 아래는 매개변수가 foo와 abc일때 실제로 생성된 코드이다.:
SELECT col1, col2, col3 FROMfoo WHERE keycol = 'abc'
FROMfoo는 col3 칼럼에 대한 별칭(alias)으로 해석되므로, 문법적인 오류가 아니다.
앞서 테이블 이름이나 칼럼 이름을 매개변수로 사용해서는 안된다는 의견을 제시했었다. 그러나 여기는 좋은 코딩 습관에 관한 절이므로, 한번 더 강조하겠다. 저장 프로시저를 작성하면, 해당 프로시저는 SQL 개체를 참조하는 독점적인 공간이 된다. (save stored procedures that is! ?) 그럼에도 불구하고, 아래에 동적 SQL에 대한 좋은 코딩 습관의 장점을 보여주도록 general_select을 개선해 보았다.
CREATE PROCEDURE general_select @tblname nvarchar(127),
@key key_type,
@debug bit = 0 AS
DECLARE @sql nvarchar(4000)
SET @sql = 'SELECT col1, col2, col3
FROM ' + quotename(@tblname) + '
WHERE keycol = @key'
IF @debug = 1 PRINT @sql
EXEC sp_executesql @sql, N'@key key_type', @key = @key
보시는 바와 같이, 몇가지를 수정하였다.
- @tblname이 SQL injection에 쓰이는 걸 방지하기 위해 quotename()을 사용하였다. quotename()에 대한 자세한 내용은 아래를 참조하라.
- 매개변수 @debug를 첨가해서, 예기치 못한 에러가 나타나는 경우에는 @key를 사용하여 SQL 코드가 어떻게 작성되었는지 쉽게 나타낼 수 있다.
- 문자열내에 @key 값을 포함시키지 않고, sp_executesql를 사용하고 @key를 매개변수로 전달하였다. 이런 방식은 SQL injection에 대한 대비도 된다.
quotename()은 SQL 7에서 처음 도입된 내장함수(built-in function)이다. 해당 함수는 구분 식별자가 되도록 추가된 구분 기호와 함께 유니코드 문자열을 반환한다. 이 함수의 제공목적이 원래 개체 이름을 인용하기 위한 것이므로, 기본 구분자는 각괄호(squeare brackets; [])이지만, 작은 따옴표(') 혹은 큰 따옴표(")로 지정할 수도 있다. 그러므로, EXEC()를 사용해야 할 때는 SQL injection을 막기 위해 quotename()을 사용할 수 있다. SQL injection절에서 예로 들었던 search_orders 프로시저에서 몇줄을 다음과 같이 수정할 수 있다.
IF @custname IS NOT NULL
SELECT @sql = @sql + ' AND custname LIKE ' + quotename(@custname, '''')
quotename() 함수에 눈여겨 볼만한 점이 하나 더 있다.: quotename()의 입력인자는 nvarchar(129)이므로, 긴 문자열을 대상으로는 사용하지 못한다. SQL 2000에서는 다음과 같은 사용자 정의 함수를 사용할 수 있다.
CREATE FUNCTION quotestring(@str nvarchar(1998)) RETURNS nvarchar(4000) AS
BEGIN
DECLARE @ret nvarchar(4000),
@sq char(1)
SELECT @sq = ''''
SELECT @ret = replace(@str, @sq, @sq + @sq)
RETURN(@sq + @ret + @sq)
END
사용법은 아래와 같다.
IF @custname IS NOT NULL
SELECT @sql = @sql + ' AND custname LIKE ' + dbo.quotestring(@custname)
SQL 7에서는, 사용자정의 함수가 제공되지 않으므로, quotestring을 저장 프로시져로 만들어야 한다. SQL 6.5에서는 replace() 함수가 제공되지 않으므로, 별 다른 대안이 없다. (SQL 서버 MVP인 Steve Kass가 quotename() 혹은 사용자 정의함수에 대해 제안해주었음을 밝힌다.)
중복된 인용부호로 인해 야기되는 지저분함을 피하기 위한 다른 대안은, T-SQL이 큰 따옴표(")를 지원한다는 사실을 이용하는 것이다. QUOTED_IDENTIFIER를 OFF로 설정하면, 문자열 구분자로 큰 따옴표("))를 쓸 수 있다. 이 설정에 대한 가본값은 컨텐스트에 좌우되는데, 선호되는 설정값은 ON으로, 인덱스된 뷰(Indexed Views)와 계산된 열(computed column)에 대한 인덱스를 사용하기 위해서는 이 값이 반드시 ON으로 설정되어야 한다. 그러므로, 이 방법이 가장 좋은 해결책은 아니지만, 경고메시지를 보는게 싫을 경우에는, 다음과 같이 사용 가능하다.
CREATE PROCEDURE general_select @tblname nvarchar(127),
@key key_type,
@debug bit = 0 AS
DECLARE @sql nvarchar(4000)
SET @sql = 'SET QUOTED_IDENTIFIER OFF
SELECT col1, col2, col3
FROM ' + @tblname + '
WHERE keycol = "' + @key + '"'
IF @debug = 1 PRINT @sql
EXEC(@sql)
두가지 다른 인용 부호가 쓰였으므로, 해당 코드의 가독성이 높아진다. SQL 문장을 위해 작은 따옴표가 쓰였고, 포함된 문자열 리터럴로 큰 따옴표가 사용되었다.
SQL injection에 대해 보호되지 못하므로, 이 방식은 sp_executesql와 quotename()을 쓰는것 보다는 좋지 못한 방법이다. 그러나 sysadmin 을 위한 작업인 관계로 SQL injection이 문제되지 않을 경우에는 사용가능하며, SQL 6.5 환경에서는 아마도 최선의 방법일 것이다.
이 절에서 제시된 가이드라인을 따르더라도, SQL 코드에 동적 SQL을 사용함으로써 야기되는 복잡성은 상당하다. 따라서, 사용하기 전에 반드시 시용해야 하는지 재고해보기 바란다는 말로 끝을 맺겠다.
동적 SQL을 사용(하지 말아야)하는 일반적인 경우 (Common Cases when to (Not) Use Dynamic SQL)
SQL 서버에 관한 여러 뉴스그룹에서, 거의 매일 간단한 예와 함께 동적 SQL을 사용하라는 답변을 받는 사람들이 종종 있다. 하지만, 답변하는 사람들 조차도 권한 및 캐싱에 관련된 숨겨진 의미를 말해주는 것을 잊곤 한다. 많은 경우에 이런 질문들에 대해 동적 SQL이 유일한 해법이기는 하지만, 실제로는 완전히 다른 – 그러고 훨씬 더 좋은 – 해결책이 존재하는 경우도 있다.
이 절에서는 동적 SQL을 사용할 수 있는 몇가지 경우와, 동적 SQL이 적절한 해결책인 경우에 대해 살펴볼 것이다. 그리고, 다른 한편으로 동적 SQL이 좋지 못한 선택인 경우에 대해서도 살펴볼 것이다.
select * from @tablename
일반적인 질문은 왜 다음 쿼리가 작동하지 않는지에 관한 것이다:
CREATE PROCEDURE my_proc @tablename sysname AS
SELECT * FROM @tablename
이러한 경우에 동적 SQL을 이용하여 해결할 수 있다는 것을 이미 알고 있지만, 이런 식의 저장 프로시저의 사용은 의미없는 일이라는 것도 또한 알고 있다. 만약 SQL 프로그래밍을 이렇게 한다면, 저장 프로시저를 사용하기 위해 골치아파할 필요가 전혀 없다.
사람들이 이러한 작업을 하고 싶어하는데는 몇가지 이유가 있어 보인다. C++, VB등 다른 프로그래밍 언어에서의 경험이 있으나 SQL 프로그래밍이 처음인 사람들이 보통 이런 식으로 작업을 많이한다. (※ 역주 : ASP개발자들도 마찬가지죠 ^^;) 테이블 이름을 매개변수로 사용하는 것은 재사용 가능한 범용 코드(Generic Code)를 만들기 위해서, 그리고 유지보수 편의성을 높힌다는 측면에서 환영할만한 방식이다.
그러나 데이타베이스 개체에 대해서는, 이 오래된 진리가 통하지 않는다. 개발자는 각각의 테이블과 칼럼들을 유일하고 고정적인 개체로 보아야 한다. 왜 그럴까? 실행계획을 세울 때, 각각의 테이블은 고유의 통계값과 추정치를 가지고 있으며, SQL 서버에서 이러한 값은 상호 교환 가능한 값이 아니다. 복잡한 데이타 모델에서는, 현재 무엇이 사용되고 있는 가를 파악하는 것이 중요하다. 테이블 이름과 칼럼이름을 매개변수로 사용한다면, 이러한 관계를 파악하기기 어려워 진다.
코딩하면서 타이프하는 수고를 덜기 위한 목적으로 이런 식의 작업이 하고 싶다면(SELECT * 같은 코드는 실제 생산환경에서 사용되어서는 안된다는 것을 기억하라), 그것은 잘못된 선택이다. 이런 경우에는 서로 유사하더라도, 이름이 다른 10개 혹은 20개의 저장 프로시저를 작성하는 것이 훨씬 더 좋은 방법이다.
만약 SQL 문이 너무 복잡해서, 서로 다른 테이블들이 사용되더라도 한 군데서 관리하는 것이 유지보수 측면에 상당한 장점이 있다면, 고려될 수 있는 다른 실용적인 방법이 있다 : C/C++과 같은 전처리기를 사용하는 것이다. 테이블당 하나의 프로시저가 존재하더라도, 코드는 하나의 파일로 만들 수 있다.
select * from sales + @yymm
앞에서 든 예의 변형에 해당한다. 차이점은 앞 절에서는 유한한 갯수의 테이블이 있는 것으로 가정했다는 것이다. 만약 테이블들이 동적으로 생성되는 시스템이라면 어떻게 할까? 예를 들어 판매 자료를 위한 테이블이 매달 생성된다면? 이런 경우에, 테이블당 하나의 저장 프로시저를 생성시킨다는 것은 전처리기를 사용하더라도 사실상 불가능하게 된다.
그렇다면, 다른 대안이 없으므로 그냥 동적 SQL을 사용해야 할까? 아니다. 되돌아가서 이 상황을 다시한번 살펴보자. 사실 처음부터 잘못된 접근법이 사용되었다. 데이타 모델에 명백한 결함이 존재하는데, 월별로 하나의 테이블을 사용하는 것은 Access를 사용하는 시스템 혹은 파일 데이타 시스템에서 성능을 향상시키기 위해 사용가능한 방법이다. SQL 서버 혹은 기타 고급 RDBMS에서 이렇게 해야할 이유는 거의 존재하지 않는다. SQL 서버 혹은 그 경쟁제품은 막대한 양의 데이타를 처리하고 그 데이타를 키를 이용하여 효율적으로 관리하기 위해 고안되었다. 연(year) 혹은 월(month)은 sales 테이블의 PK(Primary Key)를 구성하는 요소일 뿐이다.
만약, 선임자로부터 이러한 시스템을 인계받은 경우에는, 리모델링을 위해 막대한 비용이 필요할 경우도 있다. (하지만 동적 SQL을 사용하므로써 발생되는 복잡한 코드에 소요되는 비용 또한 무시하지 못한다.) 만약 새로운 시스템을 개발하고 있다면, 동적으로 생성되는 테이블에 대해서는 잊어버려라. 그러한 테이블에 접근하거나 업데이트하기 위한 코드가 상당히 지저분해 질 것이다. 이를 테면 전자상거래 시스템에서 각 장바구니당 하나의 테이블을 생성시키는 것처럼 이러한 테이블을 자주 생성시킨다면, 시스템 테이블에 핫 스폿(※ 역주 : Hot Spot은 많은 Query들이 동시에 동일한 영역의 디스크에 데이터를 읽거나 쓰려고 하는 경우에 발생합니다. 이는 하드 디스크가 동시에 처리할 수 있는 것보다 많은 디스크 I/O 요청들을 받게 되기 때문에, 디스크 I/O 병목현상(Bottleneck)을 유발하게 됩니다. 참고: KB 601427)을 유도해 성능에 악영향을 미칠 수도 있다.
수백만개의 데이타가 있는데, 한 테이블에 모든 데이타를 저장해두면, 데이타베이스가 작동하지 않을꺼야 라며 아직도 수긍하지 못하고 궁시렁거릴 독자가 있을 것이다. 좋다. 테이블에 정말로 많은 행(rows)이 존재한다고 치자. 신경쓸 일이 많지? 그치만, 그건 수백만개의 데이타때문이 아니라, SQL 서버 관리를 위해 매일 해야 하는 당연한 업무이다. (인덱스가 현명하게 정의되었다고 가정한 것이다.) 일억개 이상의 행이 존재한다면, 고려해야할 다른 문제가 생긴다. 이런 목적을 위해, SQL 2000은 분할 뷰(partitioned views) 혹은 분산분할 뷰(distributed partitioned views)와 같은 몇가지 특성을 지원한다. 분할 뷰 혹은 분산분할 뷰를 이용하면, 큰 데이타 집합을 몇개의 테이블로 나눌 수 있고, 마치 하나의 테이블처럼 접근할 수 있게 해준다. (주의 : 정확한 표현을 위해서는 행의 갯수가 아닌 테이블의 크기(total size)에 대해 언급해야 한다. 물론 테이블의 크기는 행의 평균 크기와 밀접한 관계가 있다.)
update tbl set @colname = @value where keycol = @keyval
이 경우는, 실행시간에 선택되는 칼럼에 대한 update가 필요한 경우이다. 위의 T-SQL은 문법에 어긋나지 않지만, 실제 일어나는 일은 테이블에서 keycol의 값이 @keyval인 행들의 @value값이 변수 @colname에 대입되는 것 뿐이다.(※ 역주 : 실제로 실행시켜보면 에러메시지가 표시되지는 않지만, 테이블의 해당 레코드에 대한 update가 수행되는 것이 아니라, @colname 변수에 할당된 값이 update될 뿐입니다.)
이 경우에 동적 SQL을 사용하려면 사용자는 테이블에 대한 Update 권한을 갖고 있을 것이 요구된다. 이런 권한 설정은 가볍게 볼 수 있는 문제가 아니며 가능하면 피해야 하는 구성이다. 여기에는 상당히 간단한 해결책이 존재한다.
UPDATE tbl
SET col1 = CASE @colname WHEN 'col1' THEN @value ELSE col1 END,
col2 = CASE @colname WHEN 'col2' THEN @value ELSE col2 END,
...Case에 익숙하지 않다면, 온라인 도움말을 참조하기 바란다. Case는 SQL의 상당히 강력한 특징중 하나이다.
여기서 왜 사람들이 이런 식의 작업을 하고 싶어하는지 살펴보자. 아마도 테이블이 다음과 같은 구조를 갖고 있어서일 것이다.:
CREATE TABLE products (prodid prodid_type NOT NULL,
prodname name_type NOT NULL,
...
sales_1 money NULL,
sales_2 money NULL,
...
sales_12 money NULL,
PRIMARY KEY (prodid))
이 경우에는 테이블을 분리하여 자식 테이블의 sales_n 칼럼을 이용하는 것이 보다 합리적이다.:
CREATE TABLE product_sales (prodid prodid_type NOT NULL,
month tinyint NOT NULL,
sales money NOT NULL,
PRIMARY KEY (prodid, month))
select * from @dbname + '..tbl'
이 경우는 테이블이 동적으로 결정되는 다른 데이타베이스에 있는 경우이다. 이런 작업방식에는 여러가지 이유가 있으며, 왜 이렇게 작업해야 하는가 하는 이유에 따라 해결책이 다르다.
다른 데이타베이스에서의 데이타 획득 만약 응용프로그램에서 사용하는 데이타가 어떤 이유로 2개이상의 데이타베이스에 분산되어 있다면, 데이타베이스 이름을 코드에 직접 참조시켜 고생할 필요가 없다. 왜냐하면, 테스트 환경에서 같은 서버에 존재하는 데이타베이스 이름이 실제 환경에서는 다른 서버에 존재할 수도 있기 때문이다. 이런 경우에는 설정 테이블에 다른 데이타베이스의 이름을 넣어두고 동적 SQL을 활용하는 것도 좋은 아이디어이지만, 다른 해결책 역시 존재한다. 만약 다른 데이타베이스에 대한 작업이 해당 저장프로시저 내에서 가능하다면, 다음과 같은 할 수 있다:
SET @sp = @dbname + '..some_sp'
EXEC @ret = @sp @par1, @par2...
저장 프로시저의 이름이 변수 @sp 값에 들어있다.
모든 데이타베이스를 대상으로 작업 이 경우는 아마도 sysadmin 고정서버 역할에 속한 사용자가 수행하는 작업일 것이다. 이런 경우에는 권한문제 혹은 캐쉬에 신경쓸 필요가 없기 때문에, 대개의 경우에 동적 SQL은 적절한 선택이다. 그럼에도 불구하고 다음 예제에서의 sp_MSforeachdb 같은 대안이 존재한다.:
sp_MSforeachdb 'SELECT ''?'', COUNT(*) FROM sysobjects'
추측하는 바와 같이, sp_MSforeachdb는 동적 SQL 을 내부적으로 사용하므로, 개발자가 일일이 루프(loop) 코드를 작성하지 않아도 되는 장점이 있다. 덧붙여 말하고 싶은 것은, sp_MSforeachdb가 온라인 도움말에서 누락된 함수라는 점이다. 온라인 도움말에서 누락된 함수를 사용했을 때 문제가 발생하면 Microsoft로부터의 기술지원을 받을 수 없다.
"마스터" 데이타베이스 간혹, 동일한 테이블 구조를 가진 여러개의 데이타베이스를 관리하는 경우를 볼 수 있다. ASP 서비스(provider service)를 제공하거나, 혹은 고객 각각에 대해 별도의 데이타베이스가 존재하는 경우에 해당하며, 사업적인 이유로 모든 고객에 대한 데이타를 하나의 데이타베이스에 두는 것이 불가능하다. 이런 경우에 관리자들은 모든 데이타베이스에 대한 유지보수가 쉽지 않다고 느끼게 되며, 결과적으로 필요한 모든 프로시저를 저장해둘 "마스터" 데이타베이스가 필요하게 된다. 그러나, "마스터" 데이타베이스에 존재하는 저장프로시저는 동적 SQL을 필요로 하며, 또다른 끔찍한 유지보수 문제를 낳게 된다.
2가지 방법이 있는데, 하나는 SQL 서버에 기본 제공되는 Master 데이타베이스를 이용하여 사용자가 작성한 프로시저를 시스템 프로시저로 설치하는 것이다. (※ 역주: master 데이타베이스에 접두어 "sp_"로 시작하는 사용자 저장프로시저를 작성해 두면, 마치 시스템 저장프로시저처럼 다른 데이타베이스에서 사용가능하게 됩니다.) 하지만, 이렇게 하면 Microsoft에서 기술지원을 기대할 수 없으며, 보안 측면에서의 문제점도 존재하므로, 권장하고 싶은 방법은 아니다.
다른 방법? 저장 프로시저를 각각의 데이타베이스에 설치하고, SQL 개체에 대한 배포 루틴(Rollout Routines)을 개발하는 것이다. 테이블을 변경해야 할 필요가 생길 것으므로, 결국에는 이 방법이 필요하게 될 것이다. 게다가 개별 데이타베이스에 저장 프로시저를 만들어두면, 새로운 버젼으로 업그레이드하기를 꺼리는 고약한 고객들에 대한 대응도 가능해지며, 까다로운 고객을 위해 특정 목적에 맞는 프로시저를 제작하는 것이 가능해진다. 배포 루틴을 적용하는 방법은 설징 유지관리(configuration management)에 관한 주제까지 다루어야 하며, 이 기사의 범위를 벗어난다. 이에 대해서는 2가지 단서만 제공하겠다. SQL Server Resource Kit에 들어있는 Stored Procedure Builder를 사용하면, Visual SourceSafe를 이용하여 SQL 개체를 설치하는 것이 가능해진다. 내 경우에는 고객들에 대한 기술지원을 제공하기 위해 AbaPerls라는 툴을 몇년 동안 개발했으며, http://www.abaris.se/abaperls/에서 구할 수 있다. 이 툴은 프리웨어이다.
select * from tbl where col in (@list)
매우 흔한 질문으로, 동적 SQL을 사용하세요가 또한 일반적인 답변이다. 하지만 이 질문에 대해 동적 SQL을 사용하라는 것은 분명히 잘못된 답변으로, 이런 종류의 Select 권한이 필요하지도 않으며, @list에 많은 요소가 포함될 경우에는, 동적 SQL을 사용할 경우 틀림없이 성능저하를 경험하게 된다.
대안? 사용자 정의함수 혹은 저장프로시저를 사용해서 입력되는 문자열을 테이블에 나누어 저장해라. 이 기사에는 적당한 예가 포함되어 있지 않지만, 또다른 기사인 Arrays and Lists in SQL Server에서 이러한 문제를 다루는 방법과 여러 방법론들의 성능차이에 대한 자료를 제시하겠다. (제시된 방법들중 동적 SQL이 가장 하위에 있다!) 해당 기사는 매우 긴 분량으로, 기사의 첫부분에 각 SQL 버전에 적합한 내용으로 분기할 수 있는 링크를 제시하였다.)
select * from tbl where @condition
다음과 같은 프로시저를 작성하려 한다고 가정해 보자.
CREATE PROCEDURE search_sp @condition varchar(8000) AS
SELECT * FROM tbl WHERE @condition
그냥 관둬라. 이런 작업을 하고 있다면 저장 프로시저를 어중간한 상태로 사용하고 있는 것으로, 개발자가 여전히 클라이언트에서 SQL 코드를 조합하고 있는 것이다. 이 예는 다음 주제와 관련있다.
동적 검색 조건 (Dynamic Search Conditions)
사용자가 광범위한 매개변수로 부터 데이타를 검색하는 것은 드문 경우가 아니다. 입력 매개변수 각각의 조합에 대하여 최적화된 쿼리를 작성해내는 정적인 해결책을 만들어내는 것이 불가능하다는 데에는 논쟁의 여지가 없다. 그리고, 대부분의 프로그래머들이 모든 조건들을 "똑똑한" SQL을 이용하여 하나의 쿼리로 묶어낸 경우에 좋은 효율을 보여주리라고 기대하지도 않는다.
이런 유형의 문제에는 동적 SQL이 분명 더 좋은 해결책이다. 권한 문제만 해결할 수 있다면, 동적 SQL을 사용하는 것이 성능 및 유지비용 보수면에서 더 낫다. 분리된 다른 기사 동적 검색 조건 (Dynamic Search Conditions) 에서 동적 SQL을 사용하는 방법과 사용하지 않고 구현하는 방법에 대한 예를 들어보겠다.
select * from table order by @col
이 경우는 동적 SQL을 사용하지 않고 다음과 같이 처리하는 것이 가능하다:
SELECT col1, col2, col3
FROM tbl
ORDER BY CASE @col1
WHEN 'col1' THEN col1
WHEN 'col2' THEN col2
WHEN 'col3' THEN col3
END
다시 한번 말하지만, 이해가 가지 않는다면 온라인 도움말의 Case 표현을 참조하라.
열(column)의 데이타 형태가 다른 경우에는 하나의 Case 표현식으로 나타낼 수 없다는 점을 기억하라. 이런 경우에는 다음과 같이 처리할 수 있다.:
SELECT col1, col2, col3
FROM tbl
ORDER BY CASE @col1 WHEN 'col1' THEN col1 ELSE NULL END,
CASE @col1 WHEN 'col2' THEN col2 ELSE NULL END,
CASE @col1 WHEN 'col3' THEN col3 ELSE NULL END
이 주제에 대해 SQL Server MVP인 Itzik Ben-Gan이 SQL Server Magazine 2001년 3월호에서 투고한 좋은 기사에서 다른 해결책을 제시하였다.
select top @n from table order by @col
동적 SQL을 사용하지 않는 간단한 방법이 아래에 나와있다.:
CREATE PROCEDURE get_first_n @var int WITH RECOMPILE AS
SET ROWCOUNT @var
SELECT *
FROM authors
ORDER BY au_id
SET ROWCOUNT 0
SQL 옵티마이저는 SET ROWCOUNT 옵션 설정값을 무시한다고 배웠을 수 있다. TOP이 제공되지 않아 다른 대안이 존재하지 않았던 SQL 6.5에서는 이 말이 사실이었다. 하지만 SQL 7과 SQL 2000에서는 그렇지 않다. 그러므로, SET ROWCOUNT의 입력값으로 사용하기 위해 매개변수(지역변수가 아닌)를 주의해서 사용하지 않는다면, 옵티마이저는 그 값을 인식하지 못하고 테이블 스캔을 하려고 할 것이다.
해당 프로시저 내의 다른 SQL문에도 영향을 미치게 되므로, Select 문 다음에 SET ROWCOUNT 0을 사용해야 한다는 점도 주의하라.
온라인 도움말에 보면 SET ROWCOUNT에 대한 참고 사항이 나와있는데, SET ROWCOUNT를 Delete, Insert 및 Update 문과 함께 사용하는 것을 권장하지 않는다. 정확히 왜 그런지는 잘 모르겠으나, SET ROWCOUNT 옵션이 설정된 상태에서 임시 테이블에 대한 INSERT는 괜찮다는 것을 제안하고 싶다.(?) ROWCOUNT 옵션 설정값은 트리거에도 영향을 미치기 때문에, 트리거가 걸린 테이블에 대한 Insert는 엉뚱한 결과를 일으킬 수 있다.
왜 이 기능을 사용해야 하는지 살펴보는 것은 의미있는 일이 될 것이다. 만약 웹페이지에 출력할 경우, 한번에 500개의 행을 읽어들여서 전체 데이타베이스를 뒤지지 않게 하는 것은 좋은 전략이다. 사용자는 다음 화면을 볼 때 "Next" 버튼을 클릭하면 된다. (개인적으로는, 한번에 보여지는 결과를 10-20개로 제한해놓은 웹사이트를 좋아하지 않는다.)
create table @tbl
이 경우는 권한 혹은 캐쉬와 관련된 문제가 없으며(동적 SQL을 사용하지 않더라도, 저장 프로시저에서 사용자가 테이블 생성권한을 필요로 하기 때문이다.) 의존성 문제와도 관련이 없다. 이 목적으로 동적 SQL을 사용하는 것에 대한 별다른 논쟁거리는 없다.
그럼에도 불구하고 여전히 다음과 같은 질문은 남아있다: 왜? 왜 이런 식으로 작업해야 하는가? 서로 유사한 일련의 테이블을 생성시킬 필요가 있는 관리자용의 스크립트 제작을 위한 작업인 경우는 의미있다. 하지만 응용프로그램에서 실시간으로 테이블을 생성시켜야 한다면, 이것은 데이타베이스 디자인의 기본사항을 망각한 것이다. 관계형 데이타베이스에서 테이블 및 칼럼은 고정적인 개체인 것으로 가정된다. 새로운 버전의 설치시에는 변경될 수 있겠지만, 실행시간에 변경되어서는 안된다. select * from sales + @yymm에서 이 주제에 대해 살펴보라.
간혹 임시로 사용되는 테이블의 이름을 유일하게(unique) 주기 위해 이런 작업방식을 사용하는 사람을 보는 경우도 있는데, 이것은 SQL 서버에서 기본적으로 제공되는 기능으로, 불필요한 작업이다. 다음과 같이 사용하면 된다:
CREATE TABLE #nisse (a int NOT NULL)
실제 테이블 이름은 보여지는 것보다 훨씬 긴 이름이 사용되며, 다른 사용자는 #nisse의 인스턴스를 들여다볼 수 없다.
Disconnected record sets를 사용하거나 혹은 임시 테이블을 사용할 수 없는 경우, 연결(connection)에 대해 유일한 테이블을 사용하고 싶다면 모든 클라이언트가 공유할 수 있고, 각각의 클라이언트를 의미하는 키값을 가지는 칼럼을 추가한 영구 테이블을 사용하는 편이 더 낫다.
Linked servers
이것은 데이타베이스 이름을 변수로 사용하고자 하는 문제와 유사하지만, 해결책은 다르다. 연결된 서버에 저장 프로시저를 정의하는 것이 가능하다면, 저장 프로시저의 이름을 동적으로 사용하는 것 또한 가능하다.:
SET @sp = @server + 'db.dbo.some_sp'
EXEC @ret = @sp @par1, @par2...
로컬에 존재하는 테이블과, 연결된 서버의 유동적으로 결정되는 원격 테이블에 대해 조인작업을 수행하고 싶다면, 동적 SQL이 아마도 가장 좋은 방법일 것이다.
비록 특정 환경에서 사용가능한 방법이긴 하지만 여기에도 여전히 대안이 존재한다. 다음에서 인용된 예와 같이, sp_addlinkedserver에서 별칭을 만들 수 있다.
EXEC sp_addlinkedserver MYSRV, @srvproduct='Any',
@provider='SQLOLEDB', @datasrc=@@SERVERNAME
go
CREATE PROCEDURE linksrv_demo_inner WITH RECOMPILE AS
SELECT * FROM MYSRV.master.dbo.sysdatabases
go
EXEC sp_dropserver MYSRV
go
CREATE PROCEDURE linksrv_demo @server sysname AS
IF EXISTS (SELECT * FROM master..sysservers WHERE srvname = 'MYSRV')
EXEC sp_dropserver MYSRV
EXEC sp_addlinkedserver MYSRV, @srvproduct='Any',
@provider='SQLOLEDB', @datasrc=@server
EXEC linksrv_demo_inner
EXEC sp_dropserver MYSRV
go
EXEC linksrv_demo 'Server1'
EXEC linksrv_demo 'Server2'
2개의 프로시저가 사용되었는데, 내부의 프로시저는 실행시간에 조회하려고 하는 연결된 서버의 별칭으로 MYSRV를 사용하였고, 작업이 완료되면 별칭을 없앤다. 내부의 프로시저에 링크드 서버에 실제로 접속하기 위한 코드가 포함되어 있다. 다른 서버를 가리키는 실행계획이 필요하지 않다는 것을 확실히 하기 위해 WITH RECOMPILE 옵션을 사용하였다.
위의 예는 다음과 같은 조건에서만 사용가능하다.:
- 프로시저는 연결된 서버를 구성할 수 있는 권한을 가진 사용자에 의해 실행되어야 한다. 일반적으로 sysadmin 혹은 setupadmin 고정서버역할이 이런 권한을 갖고 있다. 그러므로, 일반 사용자에게는 적용되지 않는다.
- 서버에 영향을 미치는 정의를 변경하는 것이므로, 실행되는 프로시져에 대한 여러개의 인스턴스를 실행시킬 수 없다. (말할 필요도 없이, 해당 별칭은 이 프로시져 내부에서만 사용하여야 한다.)(?)
주의: If you test are likely to find that it works without WITH RECOMPILE.. You may get it work to have the call to sp_addlinkedserver in the same procedure as the reference to the linked server, but if the linked server is not defined when SQL Server needs to build a query plan for the procedure, the procedure will fail..
OPENQUERY
행집합(row-set)을 반환하는 함수인 Openquery와 Openrowset을 사용할 때는 종종 동적 SQL이 필요하다. 해당 함수들의 2번째 매개변수는 SQL문으로, 변수를 사용할 수 없다. 작은 따옴표를 여러번 사용해야 하는 문제로 종종 혼란스럽기도 한데, 이전에 제시한 quotestring()을 사용하면 많은 도움이 될 것이다.
DECLARE @remotesql nvarchar(4000),
@localsql nvarchar(4000),
@state char(2)
SELECT @state = 'CA'
SELECT @remotesql = 'SELECT * FROM pubs.dbo.authors WHERE state = ' +
dbo.quotestring(@state)
SELECT @localsql = 'SELECT * FROM OPENQUERY(MYSRV, ' +
dbo.quotestring(@remotesql) + ')',
PRINT @localsql
EXEC (@localsql)
SQL문의 길이가 입력한계인 129자를 넘는 경우가 많기 때문에, 내장함수인 quotename()은 쓰이지 못하는 경우가 많다.
열의 너비를 동적으로 변화시키고자 할 때 (Dynamic Column Widths)
쿼리 분석기에서 실행되며, 어떤 종류의 데이타 출력을 위한 저장 프로시저를 생각해보자 (아마도 대부분 관리자용 프로시져일 것이다.) 결과를 잘 볼 수 있게 하려면 데이타가 짤려서 보이지 않도록 열의 너비가 충분해야 하지만, 필요이상의 공간이 보여질 필요도 없다. 이런 경우 동적 SQL을 활용하여 해결할 수 있다. 대개 이런 작업은 임시테이블을 사용하게 되는데, 권한 문제를 신경쓰지 않아도 무방하기 때문이다.
여기서 예제를 제시하지는 않았지만, 온라인 도움말에 나오지는 않지만 많이 알려져 있는 시스템 프로시저 sp_who2가 가장 접하기 쉬운 예이다. exec master..sp_helptext sp_who2 쿼리를 실행시키거나, 쿼리분석기 혹은 EM의 개체 브라우저를 사용하여 코드를 직접 볼 수 있다.
aba_lockinfo에서도 다른 예를 찾아볼 수 있다.
감사의 글
이 기사를 쓰기 위해 유용한 제안과 정보를 제공해준 Pankul Verma, Marcus Hansfeldt, Jeremy Lubich, 그리고 SQL Server MVP인 Tibor Karaszi, Keith Kratochvil, Steve Kass, Umachandar Jaychandran, Hal Berenson에게 감사드리고 싶다.
기사의 내용, 언어, 형식에 대한 첨가 혹은 수정제안은, esquel@sommarskog.se로 메일을 보내주기 바란다. 기술적인 질문에 답변해줄 사람을 찾는다면, microsoft.public.sqlserver.programming 혹은 comp.databases.ms-sqlserver와 같은 뉴스그룹을 이용하실 것을 권해 드린다.(※ 역주 : 한글 뉴스그룹 주소는 microsoft.public.kr.sql입니다.)
원본 최종 수정시간 03-12-02
번역본 최종 수정시간 04-08-04